Prima componentă principală. Metoda componentei principale: definiție, aplicare, exemplu de calcul. Normalizare după reducerea la componentele principale
Analiza componentelor se referă la metode de reducere a dimensionalității multidimensionale. Conține o singură metodă - metoda componentei principale. Componentele principale sunt sistem ortogonal coordonate în care varianţele componentelor le caracterizează proprietăţile statistice.
Având în vedere că obiectele de cercetare în economie se caracterizează printr-un număr mare, dar finit de caracteristici, a căror influență este supusă unui număr mare de cauze aleatorii.
Calculul componentelor principale
Primul componenta principală Z1 din sistemul studiat de caracteristici X1, X2, X3, X4,..., Xn se numește o astfel de combinație liniară centrată - normalizată a acestor caracteristici, care, printre alte combinații liniare centrate - normalizate ale acestor caracteristici, are cea mai variabilă dispersie.
Ca a doua componentă principală Z2 vom lua o astfel de combinație centrată - normalizată a acestor caracteristici, care:
nu este corelat cu prima componentă principală,
nu sunt corelate cu prima componentă principală, această combinație are cea mai mare varianță.
Vom numi K-a componentă principală Zk (k=1…m) o astfel de combinație centrată - normalizată de caracteristici, care:
nu este corelat cu componentele principale anterioare k-1,
dintre toate combinațiile posibile de caracteristici inițiale care nu sunt
nu sunt corelate cu componentele principale anterioare k-1, această combinație are cea mai mare varianță.
Să introducem matricea ortogonală U și să trecem de la variabilele X la variabilele Z și
Vectorul este selectat astfel încât dispersia să fie maximă. După obținere, so se selectează astfel încât varianța să fie maximă, cu condiția să nu fie corelată cu etc.
Deoarece caracteristicile sunt măsurate în cantități incomparabile, va fi mai convenabil să treceți la cantități centrate-normalizate. Găsim matricea valorilor inițiale centrate-normalizate ale caracteristicilor din relația:

unde este o estimare imparțială, consecventă și eficientă a așteptărilor matematice,
Estimarea varianței imparțială, consecventă și eficientă.
Matricea valorilor observate ale caracteristicilor inițiale este dată în Anexă.
Centrarea și normalizarea au fost efectuate cu ajutorul programului „Stadia”.
Deoarece caracteristicile sunt centrate și normalizate, matricea de corelație poate fi estimată folosind formula:

Înainte de a efectua analiza componentelor, vom analiza independența caracteristicilor inițiale.
Verificarea semnificației matricei de corelație perechi folosind testul Wilks.
Propunem o ipoteză:
H0: nu este semnificativ
H1: semnificativ
125,7; (0,05;3,3) = 7,8
deoarece > , atunci ipoteza H0 este respinsă și matricea este semnificativă, prin urmare, are sens să se efectueze analiza componentelor.
Să verificăm ipoteza despre diagonalitatea matricei de covarianță
Propunem o ipoteză:
Construim statistici, distribuite conform legii cu grade de libertate.
123,21, (0,05;10) =18,307
deoarece >, atunci ipoteza H0 este respinsă și are sens să se efectueze o analiză componente.
Pentru a construi o matrice de încărcări de factori, este necesar să găsiți valorile proprii ale matricei prin rezolvarea ecuației.
Pentru această operație folosim funcția eigenvals a sistemului MathCAD, care returnează valorile proprii ale matricei:
Deoarece datele originale sunt o mostră din populatia, atunci am primit nu valorile proprii și vectorii proprii ai matricei, ci estimările acestora. Ne va interesa cât de bine, din punct de vedere statistic, caracteristicile eșantionului descriu parametrii corespunzători pentru populația generală.
Intervalul de încredere pentru i-a valoare proprie se găsește folosind formula:

Intervalele de încredere pentru valorile proprii iau în cele din urmă forma:

Estimarea valorii mai multor valori proprii se încadrează în intervalul de încredere al altor valori proprii. Este necesar să se testeze ipoteza despre multiplicitatea valorilor proprii.
Multiplicitatea este verificată folosind statistici
unde r este numărul de rădăcini multiple.
În caz de corectitudine, această statistică este distribuită conform legii cu numărul de grade de libertate. Să propunem ipoteze:
Deoarece ipoteza este respinsă, adică valorile proprii nu sunt multiple.
Deoarece ipoteza este respinsă, adică valorile proprii nu sunt multiple.
Este necesar să se identifice componentele principale la un nivel de conținut informațional de 0,85. Măsura conținutului de informații arată ce parte sau ce proporție din varianța caracteristicilor originale este alcătuită de k-primele componente principale. Vom numi măsura conținutului informațional următoarea valoare:
La un anumit nivel de conținut informațional, sunt identificate trei componente principale.
Să scriem matricea =

Pentru a obține un vector de tranziție normalizat de la caracteristicile originale la componentele principale, este necesar să se rezolve sistemul de ecuații: , unde este valoarea proprie corespunzătoare. După obținerea unei soluții la sistem, este necesar să se normalizeze vectorul rezultat.
Pentru a rezolva această problemă, vom folosi funcția eigenvec a sistemului MathCAD, care returnează un vector normalizat pentru valoarea proprie corespunzătoare.
În cazul nostru, primele patru componente principale sunt suficiente pentru a atinge un anumit nivel de conținut informațional, deci matricea U (matricea de tranziție de la baza originală la baza vectorilor proprii)
Construim o matrice U, ale cărei coloane sunt vectori proprii:

Matricea coeficientului de ponderare:


Coeficienții matricei A sunt coeficienți de corelație între caracteristicile inițiale centrate-normalizate și componentele principale nenormalizate și arată prezența, rezistența și direcția unei relații liniare între caracteristicile inițiale corespunzătoare și componentele principale corespunzătoare.
Analiza componentelor principale (PCA) simplifică complexitatea datelor cu dimensiuni mari, păstrând în același timp tendințele și modelele. Face acest lucru prin conversia datelor în dimensiuni mai mici care acționează ca rezumate ale funcțiilor. Astfel de date sunt foarte frecvente în diferite domenii ale științei și tehnologiei și apar atunci când sunt măsurate mai multe trăsături pentru fiecare probă, cum ar fi expresia multor specii. Acest tip de date prezintă probleme cauzate de ratele crescute de eroare din cauza corecțiilor multiple ale datelor.
Metoda este similară cu gruparea - găsește modele nelegate și le analizează, verificând dacă eșantioanele provin din diferite grupuri de studiu și dacă sunt semnificativ diferite. Ca și în cazul tuturor metodelor statistice, acesta poate fi aplicat incorect. Scalarea variabilelor poate duce la rezultate diferite ale analizei și este important ca aceasta să nu fie ajustată pentru a se potrivi cu valoarea anterioară a datelor.
Obiectivele analizei componentelor
Scopul principal al metodei este de a detecta și reduce dimensionalitatea unui set de date și de a identifica noi variabile subiacente semnificative. Pentru a face acest lucru, se propune utilizarea unor instrumente speciale, de exemplu, pentru a colecta date multidimensionale într-o matrice de date TableOfReal, în care rândurile sunt asociate cu cazuri și coloane de variabile. Prin urmare, TableOfReal este interpretat ca vectori de date numberOfRows, fiecare vector având un număr de elemente Columns.
În mod tradițional, analiza componentelor principale este efectuată pe o matrice de covarianță sau o matrice de corelație, care poate fi calculată din matricea de date. Matricea de covarianță conține sumele scalate ale pătratelor și produselor încrucișate. O matrice de corelație este similară cu o matrice de covarianță, dar în ea, variabilele, adică coloanele, au fost mai întâi standardizate. Mai întâi va trebui să standardizați datele dacă variațiile sau unitățile variabilelor sunt foarte diferite. Pentru a efectua analiza, selectați matricea de date TabelOfReal din lista de obiecte și chiar faceți clic pe Go.
Acest lucru va face ca un nou obiect să apară în lista de obiecte folosind metoda componentei principale. Acum puteți reprezenta curbele de valori proprii pentru a vă face o idee despre importanța fiecăreia. Și programul poate sugera și o acțiune: obțineți ponderea varianței sau verificați egalitatea numărului de valori proprii și obțineți egalitatea acestora. Deoarece componentele sunt obținute prin rezolvarea unei anumite probleme de optimizare, ele au unele proprietăți „încorporate”, cum ar fi variabilitatea maximă. În plus, există o serie de alte proprietăți care pot oferi analiză factorială:
- varianța fiecăruia, în timp ce ponderea varianței totale a variabilelor originale este dată de valorile proprii;
- calcule de scor care ilustrează valoarea fiecărei componente atunci când este observată;
- obținerea de încărcări care descriu corelația dintre fiecare componentă și fiecare variabilă;
- corelația dintre variabilele originale reproduse folosind componenta p;
- reproducerea datelor sursă poate fi reprodusă din p-componente;
- componente „rotative” pentru a le spori interpretabilitatea.
Selectarea numărului de puncte de stocare
Există două moduri de a alege suma necesară componente de depozitare. Ambele metode se bazează pe relații dintre valorile proprii. Pentru a face acest lucru, se recomandă construirea unui grafic de valori. Dacă punctele de pe grafic tind să se alinieze și sunt suficient de aproape de zero, atunci ele pot fi ignorate. Limitați numărul de componente la numărul care reprezintă o anumită proporție din variația totală. De exemplu, dacă utilizatorul este mulțumit de 95% din variația totală, numărul de componente (VAF) este 0,95.
Componentele principale sunt obținute prin proiectarea analizei componentelor principale statistice multivariate a vectorilor de date pe spațiul vectorilor proprii. Acest lucru se poate face în două moduri - direct din TableOfReal fără a genera mai întâi un obiect PCA și apoi puteți afișa configurația sau numerele acesteia. Selectați împreună Object și TableOfReal și „Configuration”, efectuând astfel analiza în mediul propriu al componentelor.
Dacă punctul de plecare se întâmplă să fie o matrice simetrică, cum ar fi o matrice de covarianță, mai întâi se efectuează reducerea formei, urmată de algoritmul QL cu deplasări implicite. Dacă, dimpotrivă, punctul de plecare este o matrice de date, atunci este imposibil să se formeze o matrice cu sume de pătrate. În schimb, trec de la metoda mai stabilă numeric și formează expansiuni de valoare singulară. Apoi matricea va conține vectori proprii, iar elementele diagonale pătrate vor conține valori proprii.
Componenta principală este combinația liniară normalizată a predictorilor originali din setul de date Analiza componentelor principale pentru Dummies. În imaginea de mai sus, PC1 și PC2 sunt componentele principale. Să presupunem că există un număr de predictori precum X1, X2...,Xp.
Componenta principală poate fi scrisă astfel: Z1 = 11X1 + 21X2 + 31X3 + .... + p1Xp
- Z1 - este prima componentă principală;
- p1 este vectorul de sarcină format din sarcinile (1, 2.) ale primei componente principale.
Încărcările sunt limitate la o sumă pătrată egală cu 1. Acest lucru se datorează faptului că încărcările mari pot duce la variații mari. De asemenea, determină direcția componentei principale (Z1) de-a lungul căreia datele diferă cel mai mult. Acest lucru are ca rezultat o linie în spațiul de măsurare p care este cea mai apropiată de observațiile n.
Proximitatea este măsurată folosind distanța euclidiană medie pătrată. X1..Xp sunt predictori normalizați. Predictorii normalizați au o medie de zero și o abatere standard de unu. Prin urmare, prima componentă principală este o combinație liniară a variabilelor predictoare originale care surprinde varianța maximă a setului de date. Determină direcția de cea mai mare variabilitate a datelor. Cu cât variabilitatea înregistrată în prima componentă este mai mare, cu atât informațiile primite de aceasta sunt mai mari. Niciun altul nu poate avea o variabilitate mai mare decât primul principal.
Prima componentă principală are ca rezultat linia care este cea mai apropiată de date și minimizează suma pătratului distanței dintre punctul de date și linie. A doua componentă principală (Z2) este, de asemenea, o combinație liniară a predictorilor originali, care surprinde varianța rămasă în setul de date și este necorelată cu Z1. Cu alte cuvinte, corelația dintre prima și a doua componentă trebuie să fie zero. Poate fi reprezentat ca: Z2 = 12X1 + 22X2 + 32X3 + .... + p2Xp.
Dacă nu sunt corelate, direcțiile lor trebuie să fie ortogonale.
Odată ce componentele principale au fost calculate, începe procesul de predicție a datelor de testare folosindu-le. Procesul metodei componentelor principale este simplu pentru manechin.

De exemplu, trebuie să faceți o transformare la setul de testare, inclusiv funcția de centru și scară în limbajul R (ver. 3.4.2) și biblioteca sa rvest. R este un limbaj de programare gratuit pentru calcul statistic și grafică. A fost reproiectat în 1992 pentru a rezolva probleme statistice pentru utilizatori. Acesta este procesul complet de modelare după extragerea PCA.

Pentru a implementa PCA în python, datele sunt importate din biblioteca sklearn. Interpretarea rămâne aceeași pentru utilizatorii R Doar setul de date utilizat pentru Python este o versiune curățată, fără valori lipsă imputate și variabile categoriale convertite în valori numerice. Procesul de modelare rămâne același ca cel descris mai sus pentru utilizatorii R Metoda componentei principale, exemplu de calcul:

Ideea din spatele metodei componentelor principale este de a aproxima această expresie pentru a efectua analiza factorială. În loc să însumăm de la 1 la p, acum să însumăm de la 1 la m, ignorând ultima p-m termeni în sumă și obținând cea de-a treia expresie. Putem rescrie acest lucru așa cum se arată în expresia care este utilizată pentru a defini matricea încărcărilor factorilor L, care dă expresia finală în notație matriceală. Dacă sunt utilizate măsurători standardizate, înlocuiți S cu matricea de eșantion de corelație R.

Aceasta formează matricea de încărcare a factorilor L în analiza factorială și este urmată de L transpus. Pentru a estima varianțe specifice, modelul factorilor pentru matricea varianță-covarianță.
Acum va fi egal cu matricea varianță-covarianță minus LL ".

- Xi este vectorul observațiilor pentru al-lea subiect.
- S reprezintă matricea noastră de varianță-covarianță eșantion.
Atunci p sunt valorile proprii pentru această matrice de covarianță a varianței, precum și vectorii proprii corespunzători pentru această matrice.
Valori proprii S:λ^1, λ^2, ... , λ^п.
Vectori proprii S: e^1, e^2, ... , e^n.

Analiza PCA este o tehnică de analiză multivariată puternică și populară, care vă permite să examinați seturi de date multivariate cu variabile cantitative. Această tehnică este utilizată pe scară largă în metoda componentelor principale din bioinformatică, marketing, sociologie și multe alte domenii. XLSTAT oferă o funcție completă și flexibilă pentru explorarea datelor direct în Excel și oferă mai multe opțiuni standard și avansate care vor oferi o perspectivă profundă asupra datelor utilizatorului.
Puteți rula programul pe date brute sau pe matrice de diferențe, puteți adăuga variabile sau observații suplimentare, puteți filtra variabile în funcție de diverse criterii pentru a optimiza citirea cardului. În plus, puteți efectua ture. Configurați cu ușurință cerc de corelare, grafic de observație ca diagrame standard Excel. Trebuie doar să transferați datele din raportul de rezultate pentru a le utiliza în analiza dvs.
XLSTAT oferă mai multe metode de procesare a datelor care vor fi utilizate pe datele de intrare înainte de calculele componentelor principale:
- Pearson, un PCA clasic care standardizează automat datele pentru calcule pentru a evita influența excesivă a variabilelor cu abateri mari de la rezultat.
- Covarianța, care se ocupă de abaterile non-standard.
- Policoric, pentru date ordinale.
Exemple de analiză a datelor dimensionale
Puteți lua în considerare metoda componentelor principale folosind exemplul de executare a unei matrice de corelație simetrică sau de covarianță. Aceasta înseamnă că matricea trebuie să fie numerică și să aibă date standardizate. Să presupunem că există un set de date cu dimensiunea 300(n) × 50(p). Unde n reprezintă numărul de observații și p reprezintă numărul de predictori.
Deoarece există un p = 50 mare, poate exista o diagramă de dispersie p(p-1)/2. În acest caz, ar fi o abordare bună să selectați un subset al predictorului p(p<< 50), который фиксирует количество информации. Затем следует составление графика наблюдения в полученном низкоразмерном пространстве. Не следует забывать, что каждое измерение является линейной комбинацией р-функций.

Exemplu pentru o matrice cu două variabile. Acest exemplu de analiză a componentelor principale creează un set de date cu două variabile (lungimea majoră și lungimea diagonală) folosind date artificiale Davis.
Componentele pot fi desenate într-un grafic de dispersie după cum urmează.

Acest diagramă ilustrează ideea primei componente sau a componentei principale care oferă un rezumat optim al datelor - nicio altă linie trasată pe un astfel de diagramă de dispersie nu va produce un set de valori prezise ale punctelor de date pe linie cu mai puțină varianță.
Prima componentă are, de asemenea, aplicație în regresia pe axa principală redusă (RMA), în care se presupune că ambele variabile x și y au erori sau incertitudini sau în care nu există o distincție clară între predictor și răspuns.
Analiza componentelor principale în econometrie este analiza variabilelor precum PNB, inflația, cursurile de schimb etc. Ecuațiile acestora sunt apoi estimate din datele disponibile, în principal serii de timp agregate. Cu toate acestea, modelele econometrice pot fi utilizate pentru multe aplicații, altele decât cele macroeconomice. Astfel, econometria înseamnă măsurare economică.
Aplicarea metodelor statistice la datele econometrice relevante arată relația dintre variabilele economice. Un exemplu simplu de model econometric. Se presupune că cheltuielile lunare ale consumatorilor variază liniar cu veniturile consumatorilor din luna anterioară. Apoi modelul va consta din ecuație

Sarcina econometricianului este de a obține estimări ale parametrilor a și b. Aceste estimări ale parametrilor, atunci când sunt utilizate în ecuația modelului, prezic valorile viitoare ale consumului care vor depinde de venitul lunii precedente. Există mai multe puncte de luat în considerare atunci când dezvoltați aceste tipuri de modele:
- natura procesului probabilistic care generează datele;
- nivelul de cunoștințe despre acesta;
- dimensiunea sistemului;
- formular de analiză;
- orizontul prognozei;
- complexitatea matematică a sistemului.
Toate aceste premise sunt importante deoarece determină sursele erorilor rezultate din model. În plus, pentru a rezolva aceste probleme, este necesar să se determine o metodă de prognoză. Poate fi redus la un model liniar chiar dacă există doar un eșantion mic. Acest tip este unul dintre cele mai comune pentru care puteți crea analize predictive.
Statistici neparametrice
Analiza componentelor principale pentru datele neparametrice se referă la metode de măsurare în care datele sunt extrase dintr-o distribuție specifică. Metodele statistice neparametrice sunt utilizate pe scară largă în diferite tipuri de studii. În practică, atunci când ipoteza de normalitate a măsurătorilor nu este îndeplinită, metodele statistice parametrice pot duce la rezultate înșelătoare. În schimb, metodele neparametrice fac ipoteze mult mai puțin stricte despre distribuția pe dimensiuni.
Ele sunt de încredere, indiferent de distribuțiile subiacente ale observațiilor. Datorită acestui avantaj atractiv, au fost dezvoltate multe tipuri diferite de teste neparametrice pentru a analiza diferite tipuri de modele experimentale. Astfel de modele includ modele cu un singur eșantion, modele cu două eșantioane și modele bloc randomizate. În prezent, o abordare bayesiană non-parametrică care utilizează analiza componentelor principale este utilizată pentru a simplifica analiza de fiabilitate a sistemelor feroviare.
Un sistem feroviar este un sistem complex tipic la scară largă cu subsisteme interconectate care conțin numeroase componente. Fiabilitatea sistemului este menținută prin măsuri de întreținere adecvate, iar gestionarea eficientă a activelor necesită o evaluare precisă a fiabilității la cel mai scăzut nivel. Cu toate acestea, datele reale de fiabilitate la nivelul componentelor unui sistem feroviar nu sunt întotdeauna disponibile în practică, cu atât mai puțin completarea. Distribuția ciclurilor de viață ale componentelor de la producători este adesea ascunsă și complicată de utilizarea reală și de mediul de operare. Astfel, analiza fiabilității necesită o metodologie adecvată pentru estimarea duratei de viață a unei componente în absența datelor de defecțiune.
Metoda componentei principale în științele sociale este utilizată pentru a îndeplini două sarcini principale:
- analiză bazată pe datele cercetării sociologice;
- construirea modelelor de fenomene sociale.
Algoritmi de calcul model
Algoritmii de analiză a componentelor principale oferă o perspectivă diferită asupra structurii și interpretării modelului. Ele reflectă modul în care PCA este utilizat în diferite discipline. Algoritmul iterativ neliniar al celor mai mici pătrate parțiale NIPALS este o metodă secvențială pentru calcularea componentelor. Calculul poate fi oprit mai devreme atunci când utilizatorul consideră că sunt destui. Majoritatea pachetelor de computer tind să utilizeze algoritmul NIPALS, deoarece are două avantaje principale:
- se ocupă de datele lipsă;
- calculează secvenţial componentele.
Scopul luării în considerare a acestui algoritm:
- oferă o perspectivă suplimentară asupra a ceea ce înseamnă încărcările și scorurile;
- arată cum fiecare componentă nu depinde ortogonal de alte componente;
- arată cum algoritmul poate gestiona datele lipsă.
Algoritmul extrage fiecare componentă secvenţial, începând cu prima direcţie de cea mai mare varianţă, apoi a doua, etc. NIPALS calculează câte o componentă la un moment dat. Prima calculată este echivalentă cu t1t1, precum și cu p1p1 de vectori care ar fi găsiți din descompunerea valorii proprii sau a valorii singulare, pot gestiona datele lipsă în XX. Converge întotdeauna, dar convergența poate fi uneori lentă. Și este cunoscut și ca algoritm de putere pentru calcularea vectorilor proprii și a valorilor proprii și funcționează excelent pentru seturi de date foarte mari. Google a folosit acest algoritm pentru versiunile timpurii ale motorului său de căutare.
Algoritmul NIPALS este prezentat în fotografia de mai jos.

Estimările coeficienților matricei T sunt apoi calculate ca T=XW și, parțial, coeficienții de regresie ai pătratelor B ale lui Y pe X sunt calculați ca B = WQ. O metodă alternativă de estimare pentru porțiunile de regresie parțiale cu cele mai mici pătrate poate fi descrisă după cum urmează.

Analiza componentelor principale este un instrument de identificare a principalelor axe de varianță dintr-un set de date și vă permite să examinați cu ușurință variabilele cheie ale datelor. Aplicată corect, metoda este una dintre cele mai puternice din setul de instrumente de analiză a datelor.
Metoda componentelor principale
Metoda componentelor principale(Engleză) Analiza componentelor principale, PCA ) este una dintre principalele modalități de reducere a dimensionalității datelor, pierzând cea mai mică cantitate de informații. Inventat de K. Pearson Karl Pearson ) in. Este utilizat în multe domenii, cum ar fi recunoașterea modelelor, viziunea computerizată, compresia datelor etc. Calculul componentelor principale se reduce la calcularea vectorilor proprii și a valorilor proprii ale matricei de covarianță a datelor originale. Uneori se numește metoda componentei principale Transformarea Karhunen-Loeve(Engleză) Karhunen-Loeve) sau transformarea Hotelling (ing. Hotelling transform). Alte modalități de reducere a dimensionalității datelor sunt metoda componentelor independente, scalarea multidimensională, precum și numeroase generalizări neliniare: metoda curbelor și varietăților principale, metoda hărților elastice, căutarea celei mai bune proiecții (ing. Urmărirea proiecției), metodele „gâtului de sticlă” ale rețelei neuronale etc.
Expunerea formală a problemei
Problema analizei componentelor principale are cel puțin patru versiuni de bază:
- date aproximative prin varietăți liniare de dimensiune inferioară;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care răspândirea datelor (adică abaterea standard de la valoarea medie) este maximă;
- găsiți subspații de dimensiune inferioară, în proiecția ortogonală pe care distanța pătratică medie dintre puncte este maximă;
- pentru o variabilă aleatoare multidimensională dată, construiți o transformare ortogonală a coordonatelor astfel încât, ca rezultat, corelațiile dintre coordonatele individuale să devină zero.
Primele trei versiuni operează cu seturi finite de date. Sunt echivalente și nu folosesc nicio ipoteză despre generarea statistică a datelor. A patra versiune operează cu variabile aleatorii. Mulțimi finite apar aici ca mostre dintr-o distribuție dată, iar soluția primelor trei probleme apare ca o aproximare a „adevărata” transformare Karhunen-Loeve. Acest lucru ridică o întrebare suplimentară și nu în întregime trivială cu privire la acuratețea acestei aproximări.
Aproximarea datelor prin varietăți liniare
Ilustrație pentru celebra lucrare a lui K. Pearson (1901): puncte date pe un plan, - distanța de la linia dreaptă. Căutăm o linie directă care să minimizeze suma
Metoda componentelor principale a început cu problema celei mai bune aproximări a unui set finit de puncte prin drepte și plane (K. Pearson, 1901). Este dat un set finit de vectori. Pentru fiecare dintre toate varietățile liniare dimensionale din, găsiți astfel încât suma abaterilor pătrate de la este minimă:
,unde este distanța euclidiană de la un punct la o varietate liniară. Orice varietate liniară -dimensională poate fi definită ca un set de combinații liniare, unde parametrii se desfășoară de-a lungul liniei reale și este un set ortonormal de vectori
,unde norma euclidiană este produsul scalar euclidian sau sub formă de coordonate:
.Soluția problemei de aproximare pentru este dată de o mulțime de varietăți liniare imbricate , . Aceste varietăți liniare sunt definite de un set ortonormal de vectori (vectori componente principale) și un vector. Vectorul este căutat ca soluție la problema de minimizare pentru:
.Vectorii componentelor principale pot fi găsiți ca soluții la probleme similare de optimizare:
1) centralizați datele (scădeți media): . Acum;
La fiecare pas pregătitor, scădem proiecția pe componenta principală anterioară. Vectorii găsiți sunt ortonormalizați pur și simplu ca urmare a rezolvării problemei de optimizare descrise, totuși, pentru a preveni ca erorile de calcul să perturbe ortogonalitatea reciprocă a vectorilor componentelor principale, aceștia pot fi incluși în condițiile problemei de optimizare.
Neunicitatea în definiție, pe lângă arbitrariul banal în alegerea semnului (și rezolvă aceeași problemă), poate fi mai semnificativă și poate apărea, de exemplu, din condițiile simetriei datelor. Ultima componentă principală este un vector unitar ortogonal cu toate precedentele.
Găsirea proiecțiilor ortogonale cu cea mai mare împrăștiere

Prima componentă principală maximizează varianța eșantionului a proiecției datelor
Să ni se dea un set centrat de vectori de date (media aritmetică este zero). Sarcina este de a găsi o transformare ortogonală într-un nou sistem de coordonate pentru care următoarele condiții ar fi adevărate:
Teoria descompunerii valorii singulare a fost creată de J. J. Sylvester. James Joseph Sylvester ) în oraș și este prezentat în toate manualele detaliate despre teoria matricelor.
Un algoritm iterativ simplu de descompunere a valorii singulare
Procedura principală este de a căuta cea mai bună aproximare a unei matrice arbitrare printr-o matrice de forma (unde - - vector dimensional și - - vector dimensional) folosind metoda celor mai mici pătrate:
Soluția la această problemă este dată în iterații succesive folosind formule explicite. Pentru un vector fix, valorile care oferă un minim formei sunt determinate în mod unic și explicit din egalități:
În mod similar, cu un vector fix, se determină valorile:
Ca o aproximare inițială a vectorului, luăm un vector aleator de unitate de lungime, calculăm vectorul, apoi pentru acest vector calculăm vectorul etc. Fiecare pas reduce valoarea. Criteriul de oprire este micșorarea scăderii relative a valorii pasului de iterație funcțional minimizat () sau micimea valorii în sine.
Ca rezultat, am obținut cea mai bună aproximare pentru matrice folosind o matrice de formă (aici superscriptul indică numărul de aproximare). În continuare, scădem matricea rezultată din matrice, iar pentru matricea de deviație rezultată căutăm din nou cea mai bună aproximare de același tip etc., până când, de exemplu, norma devine suficient de mică. Ca rezultat, am obținut o procedură iterativă de descompunere a unei matrice sub forma unei sume de matrice de rang 1, adică . Presupunem și normalizăm vectorii: Ca rezultat, se obține o aproximare a numerelor singulare și a vectorilor singulari (dreapta - și stânga -).
Avantajele acestui algoritm includ simplitatea sa excepțională și capacitatea de a-l transfera aproape fără modificări ale datelor cu spații, precum și date ponderate.
Există diverse modificări ale algoritmului de bază care îmbunătățesc precizia și robustețea. De exemplu, vectorii componentelor principale pentru diferitele diferite ar trebui să fie ortogonali „prin construcție”, cu toate acestea, cu un număr mare de iterații (dimensiune mare, multe componente), se acumulează mici abateri de la ortogonalitate și poate fi necesară o corecție specială la fiecare pas, asigurându-i ortogonalitatea față de componentele principale găsite anterior.
Metoda descompunerii singulare a tensorilor și a componentei principale a tensorilor
Adesea, un vector de date are structura suplimentară a unui tabel dreptunghiular (de exemplu, o imagine plată) sau chiar a unui tabel multidimensional - adică un tensor: , . În acest caz, este, de asemenea, eficient să folosiți descompunerea valorii singulare. Definiția, formulele de bază și algoritmii sunt transferate practic fără modificări: în loc de o matrice de date, avem o valoare de index, unde primul indice este numărul punctului de date (tensor).
Procedura principală este de a căuta cea mai bună aproximare a unui tensor printr-un tensor de formă (unde este un vector -dimensional (este numărul de puncte de date), este un vector de dimensiune la ) folosind metoda celor mai mici pătrate:
Soluția la această problemă este dată în iterații succesive folosind formule explicite. Dacă toți vectorii factori sunt dați cu excepția unuia, atunci acesta rămas este determinat în mod explicit din condiții suficiente pentru minim.
Ca o aproximare inițială a vectorilor (), luăm vectori aleatori de lungime unitară, calculăm vectorul, apoi pentru acest vector și acești vectori calculăm vectorul etc. (iterând ciclic prin indici) Fiecare pas reduce valoarea lui . Algoritmul converge evident. Criteriul de oprire este micșorarea scăderii relative a valorii funcționalei minimizate pe ciclu sau micimea valorii în sine. Apoi, scădem aproximarea rezultată din tensor și căutăm din nou cea mai bună aproximare de același tip pentru restul etc., până când, de exemplu, norma următorului rest devine suficient de mică.
Această descompunere a valorii singulare cu mai multe componente (metoda componentei principale a tensorilor) este utilizată cu succes în procesarea imaginilor, a semnalelor video și, mai larg, a oricăror date care au o structură tabulară sau tensorală.
Matrice de transformare în componente principale
Matricea de transformare a datelor în componente principale constă din vectori de componente principale, aranjați în ordinea descrescătoare a valorilor proprii:
(înseamnă transpunere),Adică, matricea este ortogonală.
Cea mai mare parte a variației datelor va fi concentrată în primele coordonate, ceea ce vă permite să vă mutați într-un spațiu de dimensiuni inferioare.
Varianta reziduala
Lasă datele să fie centrate, . Când se înlocuiesc vectorii de date cu proiecția lor pe primele componente principale, eroarea medie pătrată este introdusă pentru un vector de date:
unde sunt valorile proprii ale matricei de covarianță empirică, dispuse în ordine descrescătoare, ținând cont de multiplicitate.
Această cantitate se numește varianta reziduala. Magnitudinea
numit varianță explicată. Suma lor este egală cu varianța eșantionului. Eroarea relativă pătrată corespunzătoare este raportul dintre variația reziduală și varianța eșantionului (adică proporție de varianță inexplicabilă):
Eroarea relativă evaluează aplicabilitatea metodei componentelor principale cu proiecție pe primele componente.
cometariu: În majoritatea algoritmilor de calcul, valorile proprii cu vectorii proprii corespunzători - componentele principale - sunt calculate în ordine de la cel mai mare la cel mai mic. Pentru a-l calcula, este suficient să calculați primele valori proprii și urma matricei de covarianță empirică (suma elementelor diagonale, adică variațiile de-a lungul axelor). Apoi
Selectarea componentelor principale conform regulii lui Kaiser
Abordarea țintă pentru estimarea numărului de componente principale pe baza proporției necesare a varianței explicate este întotdeauna aplicabilă formal, dar presupune implicit că nu există nicio separare în „semnal” și „zgomot”, și orice precizie predeterminată are sens. Prin urmare, o altă euristică este adesea mai productivă, bazată pe ipoteza prezenței unui „semnal” (dimensiune relativ mică, amplitudine relativ mare) și „zgomot” (dimensiune mare, amplitudine relativ mică). Din acest punct de vedere, metoda componentelor principale funcționează ca un filtru: semnalul este conținut în principal în proiecția pe primele componente principale, iar proporția de zgomot în componentele rămase este mult mai mare.
Întrebare: cum se estimează numărul de componente principale necesare dacă raportul semnal-zgomot este necunoscut în prealabil?
Cea mai simplă și mai veche metodă de selectare a componentelor principale oferă regula Kaiser(Engleză) regula lui Kaiser): acele componente principale sunt semnificative pentru care
adică depășește media (varianța medie a eșantionului a coordonatelor vectorului de date). Regula lui Kaiser funcționează bine în cazurile simple în care există mai multe componente principale cu , mult mai mari decât media, iar valorile proprii rămase sunt mai mici decât aceasta. În cazuri mai complexe, poate produce prea multe componente principale semnificative. Dacă datele sunt normalizate la variația eșantionului unitar de-a lungul axelor, atunci regula lui Kaiser ia o formă deosebit de simplă: numai acele componente principale pentru care
Estimarea numărului de componente principale folosind regula bastonului rupt

Exemplu: estimarea numărului de componente principale folosind regula bastonului rupt în dimensiunea 5.
Una dintre cele mai populare abordări euristice pentru estimarea numărului de componente principale necesare este regula bastonului rupt(Engleză) Model stick rupt). Setul de valori proprii normalizate la suma unitară (, ) este comparat cu distribuția lungimii fragmentelor unui baston de lungime unitară ruptă la al treilea punct selectat aleatoriu (punctele de rupere sunt alese independent și sunt distribuite egal pe lungimea lui). bastonul). Fie () lungimile bucăților de trestie rezultate, numerotate în ordinea descrescătoare a lungimii: . Nu este greu de găsit așteptările matematice:
După regula bastonului rupt, vectorul propriu (în ordinea descrescătoare a valorilor proprii) este stocat în lista componentelor principale dacă
În fig. Un exemplu este dat pentru cazul cu 5 dimensiuni:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.De exemplu, selectat
=0.5; =0.3; =0.1; =0.06; =0.04.Conform regulii bastonului rupt, în acest exemplu ar trebui să lăsați 2 componente principale:
Conform evaluărilor utilizatorilor, regula bastonului rupt tinde să subestimeze numărul de componente principale semnificative.
Normalizare
Normalizare după reducerea la componentele principale
După proiecția pe primele componente principale cu este convenabil să se normalizeze la varianța unitară (eșantionului) de-a lungul axelor. Dispersia de-a lungul celei de-a doua componente principale este egală cu ), prin urmare, pentru a se normaliza, coordonatele corespunzătoare trebuie împărțite la . Această transformare nu este ortogonală și nu păstrează produsul punctual. Matricea de covarianță a proiecției datelor după normalizare devine unitate, proiecțiile către oricare două direcții ortogonale devin mărimi independente și orice bază ortonormală devine baza componentelor principale (reamintim că normalizarea modifică relația de ortogonalitate a vectorilor). Maparea de la spațiul de date sursă la primele componente principale, împreună cu normalizarea, este specificată de matrice
.Această transformare este cea mai adesea numită transformarea Karhunen-Loeve. Aici sunt vectori coloană, iar superscriptul înseamnă transpunere.
Normalizare înainte de calcularea componentelor principale
Avertizare: nu trebuie confundată normalizarea efectuată după transformarea în componentele principale cu normalizarea și „nedimensionalizarea” atunci când preprocesarea datelor, efectuat înainte de calcularea componentelor principale. Este necesară o normalizare preliminară pentru a face o alegere rezonabilă a metricii în care se va calcula cea mai bună aproximare a datelor sau se vor căuta direcțiile celei mai mari împrăștiere (care este echivalentă). De exemplu, dacă datele sunt vectori tridimensionali de „metri, litri și kilograme”, atunci folosind distanța euclidiană standard, o diferență de 1 metru în prima coordonată va contribui la fel ca o diferență de 1 litru în a doua, sau 1 kg în al treilea . De obicei, sistemele de unități în care sunt prezentate datele originale nu reflectă cu acuratețe ideile noastre despre scările naturale de-a lungul axelor și se realizează „fără dimensiuni”: fiecare coordonată este împărțită într-o anumită scară determinată de date, de scopuri. a prelucrării acestora şi a proceselor de măsurare şi colectare a datelor.
Există trei abordări standard semnificativ diferite pentru o astfel de normalizare: varianța unitară de-a lungul axelor (scalele de-a lungul axelor sunt egale cu abaterile pătratice medii - după această transformare, matricea de covarianță coincide cu matricea coeficienților de corelație), pe precizie egală de măsurare(scara de-a lungul axei este proporțională cu precizia măsurării unei valori date) și pe cereri egaleîn problemă (scara de-a lungul axei este determinată de precizia necesară a prognozei unei anumite valori sau de distorsiunea permisă a acesteia - nivelul de toleranță). Alegerea preprocesării este influențată de formularea semnificativă a problemei, precum și de condițiile de colectare a datelor (de exemplu, dacă colectarea datelor este fundamental incompletă și datele vor fi încă primite, atunci este irațional să alegeți normalizarea strict la unitate. varianță, chiar dacă aceasta corespunde sensului problemei, deoarece aceasta implică renormalizarea tuturor datelor după primirea unei noi porțiuni, este mai rezonabil să alegeți o anumită scară care să estimeze aproximativ abaterea standard și apoi să nu o modificați;
Pre-normalizarea la variația unității de-a lungul axelor este distrusă prin rotația sistemului de coordonate dacă axele nu sunt componente principale, iar normalizarea în timpul preprocesării datelor nu înlocuiește normalizarea după normalizarea la componentele principale.
Analogie mecanică și analiza componentelor principale pentru datele ponderate
Dacă atribuim o unitate de masă fiecărui vector de date, atunci matricea de covarianță empirică coincide cu tensorul de inerție al acestui sistem de masă punctuală (împărțit la masa totală), iar problema componentelor principale coincide cu problema reducerii tensorului de inerție la axele principale. Puteți folosi o libertate suplimentară în alegerea valorilor de masă pentru a ține cont de importanța punctelor de date sau de fiabilitatea valorilor acestora (datele importante sau datele din surse mai sigure li se atribuie mase mai mari). Dacă vectorului de date i se da masa, atunci în loc de matricea de covarianță empirică obținem
Toate operațiunile ulterioare de reducere la componentele principale sunt efectuate în același mod ca în versiunea principală a metodei: căutăm o bază proprie ortonormală, o ordonăm în ordinea descrescătoare a valorilor proprii, estimăm eroarea medie ponderată a aproximării datelor prin prima componente (pe baza sumelor valorilor proprii), normalizare etc.
O metodă mai generală de cântărire dă maximizarea sumei ponderate a distanțelor pe perechiîntre proiecţii. Pentru fiecare două puncte de date, se introduce o pondere; Și . În loc de matricea de covarianță empirică, folosim
Când matricea simetrică este pozitivă definită, deoarece forma pătratică este pozitivă:
În continuare, căutăm o bază proprie ortonormală, o ordonăm în ordinea descrescătoare a valorilor proprii, estimăm eroarea medie ponderată a aproximării datelor de către primele componente etc. - exact la fel ca în algoritmul principal.
Se folosește această metodă dacă există cursuri: pentru clase diferite ponderea este aleasă să fie mai mare decât pentru punctele din aceeași clasă. Ca urmare, în proiecția pe componentele principale ponderate, diferitele clase sunt „depărtate” cu o distanță mai mare.
Alte utilizări - reducerea impactului abaterilor mari(alocați, engleză) Outlier ), care poate distorsiona imaginea datorită utilizării distanței pătrate medii: dacă alegeți , influența abaterilor mari va fi redusă. Astfel, modificarea descrisă a metodei componentelor principale este mai robustă decât cea clasică.
Terminologie specială
În statistică, atunci când se utilizează metoda componentelor principale, se folosesc mai mulți termeni speciali.
Matricea de date; fiecare linie este un vector preprocesate date ( centrat si drept standardizate), numărul de rânduri - (numărul de vectori de date), numărul de coloane - (dimensiunea spațiului de date);
Matricea de încărcare(Încărcări) ; fiecare coloană este un vector de componente principale, numărul de rânduri este (dimensiunea spațiului de date), numărul de coloane este (numărul de vectori ale componentelor principale selectate pentru proiecție);
Matricea contului(Scoruri); fiecare linie este o proiecție a vectorului de date pe componentele principale; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea scorului Z(scoruri Z); fiecare linie este o proiecție a vectorului de date pe componentele principale, normalizată la varianța eșantionului unitar; număr de rânduri - (număr de vectori de date), număr de coloane - (număr de vectori componente principale selectate pentru proiecție);
Matricea erorilor(sau resturi) (Erori sau reziduuri) .
Formula de baza:
Limite de aplicabilitate și limitări ale eficacității metodei
Metoda componentei principale este întotdeauna aplicabilă. Afirmația obișnuită că se aplică numai datelor distribuite în mod normal (sau pentru distribuții apropiate de normal) este incorectă: în formularea originală a lui K. Pearson problema este stabilită: aproximări set finit de date și nu există nici măcar o ipoteză despre generarea lor statistică, ca să nu mai vorbim despre distribuția lor.
Cu toate acestea, metoda nu este întotdeauna eficientă în reducerea dimensionalității, având în vedere constrângerile de precizie. Liniile drepte și planele nu oferă întotdeauna o bună aproximare. De exemplu, datele pot urma o curbă cu o bună acuratețe, dar această curbă poate fi dificil de localizat în spațiul de date. În acest caz, metoda componentelor principale pentru o acuratețe acceptabilă va necesita mai multe componente (în loc de una) sau nu va reduce deloc dimensionalitatea cu o acuratețe acceptabilă. Pentru a face față unor astfel de componente principale „curbate”, au fost inventate metoda distribuției principale și diferite versiuni ale metodei componentelor principale neliniare. Datele de topologie complexe pot cauza mai multe probleme. De asemenea, au fost inventate diverse metode pentru a le aproxima, cum ar fi hărți Kohonen auto-organizate, gaz neural sau gramaticile topologice. Dacă datele sunt generate statistic cu o distribuție foarte diferită de cea normală, atunci pentru a aproxima distribuția este util să treceți de la componentele principale la componente independente, care nu mai sunt ortogonale în produsul scalar original. În cele din urmă, pentru o distribuție izotropă (chiar și una normală), în loc de un elipsoid de împrăștiere obținem o minge și este imposibil să reducem dimensiunea prin metode de aproximare.
Exemple de utilizare
Vizualizarea datelor
Vizualizarea datelor este o reprezentare vizuală a datelor experimentale sau a rezultatelor cercetării teoretice.
Prima alegere în vizualizarea unui set de date este de a proiecta ortogonal pe un plan primele două componente principale (sau spațiul tridimensional al primelor trei componente principale). Planul de proiectare este în esență un „ecran” plat bidimensional poziționat astfel încât să ofere o „imagine” a datelor cu cea mai mică distorsiune. O astfel de proiecție va fi optimă (dintre toate proiecțiile ortogonale pe diferite ecrane bidimensionale) din trei aspecte:
- Suma pătratelor distanțelor de la punctele de date la proiecțiile pe planul primelor componente principale este minimă, adică ecranul este situat cât mai aproape de norul de puncte.
- Suma distorsiunilor pătratului distanțelor dintre toate perechile de puncte din norul de date după proiectarea punctelor în plan este minimă.
- Suma distorsiunilor pătratului distanțelor dintre toate punctele de date și „centrul lor de greutate” este minimă.
Vizualizarea datelor este una dintre cele mai utilizate aplicații ale analizei componentelor principale și ale generalizărilor sale neliniare.
Compresie imagini și video
Pentru a reduce redundanța spațială a pixelilor la codificarea imaginilor și videoclipurilor, sunt utilizate transformări liniare ale blocurilor de pixeli. Cuantificarea ulterioară a coeficienților obținuți și codarea fără pierderi permite obținerea unor rapoarte de compresie semnificative. Utilizarea transformării PCA ca transformare liniară este, pentru unele tipuri de date, optimă în ceea ce privește dimensiunea datelor rezultate, menținând în același timp aceeași distorsiune. În prezent, această metodă nu este utilizată în mod activ, în principal datorită complexității sale de calcul ridicate. Comprimarea datelor poate fi realizată și prin eliminarea ultimilor coeficienți de conversie.
Reduceți zgomotul din imagini
Chimiometrie
Metoda componentei principale este una dintre metodele principale din chimiometrie. Chimiometrie ). Vă permite să împărțiți matricea de date sursă X în două părți: „cu sens” și „zgomot”. Conform celei mai populare definiții, „Chimiometria este o disciplină chimică care aplică metode matematice, statistice și alte metode bazate pe logica formală pentru a construi sau selecta metode optime de măsurare și proiecte experimentale, precum și pentru a extrage cele mai importante informații în analiza experimentală. date."
Psihodiagnostic
- analiza datelor (descrierea rezultatelor sondajelor sau a altor studii prezentate sub formă de matrice de date numerice);
- descrierea fenomenelor sociale (construcția de modele de fenomene, inclusiv modele matematice).
În științe politice, metoda componentei principale a fost instrumentul principal al proiectului „Atlasul politic al modernității” pentru analiza liniară și neliniară a evaluărilor a 192 de țări ale lumii în funcție de cinci indici integrali special dezvoltați (standard de trai, influență internațională, amenințări). , statalitate și democrație). Pentru a mapa rezultatele acestei analize, a fost dezvoltat un GIS (Geographic Information System) special, care combină spațiul geografic cu spațiul caracteristic. Hărțile de date ale atlasului politic au fost create, de asemenea, folosind ca bază varietăți principale bidimensionale în spațiul cincidimensional al țărilor. Diferența dintre o hartă de date și o hartă geografică este că pe o hartă geografică sunt în apropiere obiecte care au coordonate geografice similare, în timp ce pe o hartă de date sunt în apropiere obiecte (țări) cu caracteristici (indici) similare.
Punctul de plecare pentru analiză este matricea de date
dimensiuni  , al cărui rând i-a caracterizează i-a observație (obiect) pentru toți k indicatori
, al cărui rând i-a caracterizează i-a observație (obiect) pentru toți k indicatori  . Datele sursă sunt normalizate, pentru care se calculează valorile medii ale indicatorilor
. Datele sursă sunt normalizate, pentru care se calculează valorile medii ale indicatorilor  , precum și valorile deviației standard
, precum și valorile deviației standard  . Apoi matricea valorilor normalizate
. Apoi matricea valorilor normalizate

cu elemente 
Se calculează matricea coeficienților de corelație perechi:

Elementele unității sunt situate pe diagonala principală a matricei  .
.
Modelul de analiză a componentelor este construit prin reprezentarea datelor normalizate originale ca o combinație liniară a componentelor principale:

Unde  - „greutate”, adică încărcarea factorilor
- „greutate”, adică încărcarea factorilor  componenta principală activată
componenta principală activată  -a variabila;
-a variabila;
 -sens
-sens  componenta principală pentru
componenta principală pentru  -observare (obiect), unde
-observare (obiect), unde  .
.
În formă de matrice, modelul are forma

Aici  - matricea componentelor principale ale dimensiunii
- matricea componentelor principale ale dimensiunii  ,
,
 - matricea încărcărilor factoriale de aceeași dimensiune.
- matricea încărcărilor factoriale de aceeași dimensiune.
Matrice  descrie
descrie  observatii in spatiu
observatii in spatiu  componentele principale. În acest caz, elementele matricei
componentele principale. În acest caz, elementele matricei  sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că
sunt normalizate, iar componentele principale nu sunt corelate între ele. Rezultă că  , Unde
, Unde  – matricea unitară a dimensiunii
– matricea unitară a dimensiunii  .
.
Element  matrici
matrici  caracterizează apropierea relaţiei liniare dintre variabila iniţială
caracterizează apropierea relaţiei liniare dintre variabila iniţială  și componenta principală
și componenta principală  , prin urmare, ia valorile
, prin urmare, ia valorile  .
.
Matricea de corelație  poate fi exprimat printr-o matrice de încărcări de factori
poate fi exprimat printr-o matrice de încărcări de factori  .
.
Unitățile sunt situate de-a lungul diagonalei principale a matricei de corelație și, prin analogie cu matricea de covarianță, ele reprezintă variațiile matricei utilizate  -caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem
-caracteristici, dar spre deosebire de acestea din urma, datorita normalizarii, aceste variatii sunt egale cu 1. Varianta totala a intregului sistem  -caracteristici ale volumului probei
-caracteristici ale volumului probei  egală cu suma acestor unități, adică egală cu urma matricei de corelaţie
egală cu suma acestor unități, adică egală cu urma matricei de corelaţie  .
.
Matricea de corelație poate fi transformată într-o matrice diagonală, adică o matrice ale cărei toate valorile, cu excepția celor diagonale, sunt egale cu zero:
 ,
,
Unde  - o matrice diagonală pe a cărei diagonală principală există valori proprii
- o matrice diagonală pe a cărei diagonală principală există valori proprii  matricea de corelatie,
matricea de corelatie,  - o matrice ale cărei coloane sunt vectori proprii ai matricei de corelație
- o matrice ale cărei coloane sunt vectori proprii ai matricei de corelație  . Deoarece matricea R este definită pozitiv, i.e. minorii săi conducători sunt pozitivi, apoi toate valorile proprii
. Deoarece matricea R este definită pozitiv, i.e. minorii săi conducători sunt pozitivi, apoi toate valorile proprii  pentru orice
pentru orice  .
.
Valori proprii  se găsesc ca rădăcini ale ecuației caracteristice
se găsesc ca rădăcini ale ecuației caracteristice

Vector propriu  , corespunzătoare valorii proprii
, corespunzătoare valorii proprii  matricea de corelare
matricea de corelare  , este definită ca o soluție diferită de zero a ecuației
, este definită ca o soluție diferită de zero a ecuației

Vector propriu normalizat  egală
egală

Dispariția termenilor non-diagonali înseamnă că caracteristicile devin independente unele de altele (  la
la  ).
).
Varianta totala a intregului sistem  variabilele din populația eșantionului rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii
variabilele din populația eșantionului rămân aceleași. Cu toate acestea, valorile sale sunt redistribuite. Procedura pentru găsirea valorilor acestor varianțe este găsirea valorilor proprii  matricea de corelație pentru fiecare dintre
matricea de corelație pentru fiecare dintre  -semne. Suma acestor valori proprii
-semne. Suma acestor valori proprii  este egală cu urma matricei de corelație, i.e.
este egală cu urma matricei de corelație, i.e.  , adică numărul de variabile. Aceste valori proprii sunt valorile de varianță ale caracteristicilor
, adică numărul de variabile. Aceste valori proprii sunt valorile de varianță ale caracteristicilor  în condiţiile în care semnele ar fi independente unele de altele.
în condiţiile în care semnele ar fi independente unele de altele.
În metoda componentelor principale, o matrice de corelație este mai întâi calculată din datele originale. Apoi se transformă ortogonal și prin aceasta se găsesc încărcările factorilor  pentru toți
pentru toți  variabile şi
variabile şi  factori (matricea încărcărilor factorilor), valori proprii
factori (matricea încărcărilor factorilor), valori proprii  și determinați ponderile factorilor.
și determinați ponderile factorilor.
Matricea de încărcare a factorilor A poate fi definită ca 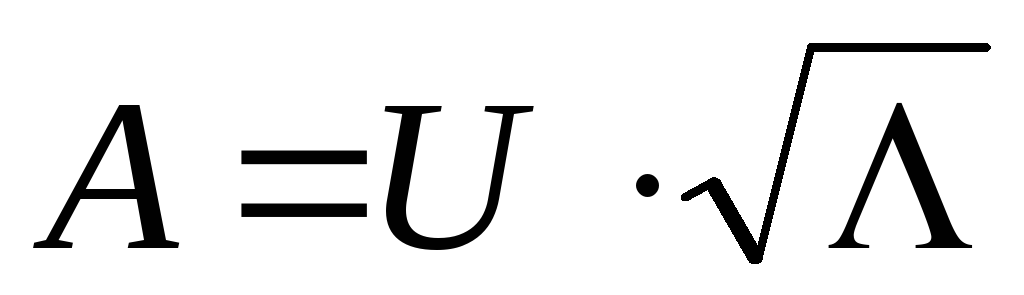 , A
, A  a-a coloană a matricei A - as
a-a coloană a matricei A - as  .
.
Ponderea factorilor  sau
sau  reflectă ponderea varianței totale contribuite de acest factor.
reflectă ponderea varianței totale contribuite de acest factor.
Încărcările factorilor variază de la –1 la +1 și sunt analoge cu coeficienții de corelație. În matricea de încărcare a factorilor, este necesar să se identifice încărcările semnificative și nesemnificative folosind testul t Student.  .
.
Suma încărcărilor pătrate  - al-lea factor în total
- al-lea factor în total  -caracteristicile este egală cu valoarea proprie a unui factor dat
-caracteristicile este egală cu valoarea proprie a unui factor dat  . Apoi
. Apoi  -contribuția variabilei i-a în % la formarea factorului j-lea.
-contribuția variabilei i-a în % la formarea factorului j-lea.
Suma pătratelor tuturor încărcărilor de factori pentru un rând este egală cu unu, varianța totală a unei variabile și a tuturor factorilor pentru toate variabilele este egală cu varianța totală (adică, urma sau ordinea matricei de corelație, sau suma valorilor sale proprii)  .
.
În general, structura factorială a atributului i-lea este prezentată sub formă  , care include doar sarcini semnificative. Folosind matricea încărcărilor factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a populației eșantionului inițial folosind formula:
, care include doar sarcini semnificative. Folosind matricea încărcărilor factorilor, puteți calcula valorile tuturor factorilor pentru fiecare observație a populației eșantionului inițial folosind formula:
 ,
,
Unde  – valoarea factorului j-a pentru a-a-a observație,
– valoarea factorului j-a pentru a-a-a observație,  -valoarea standardizată a i-a trăsătură a observației a-a a eșantionului original;
-valoarea standardizată a i-a trăsătură a observației a-a a eșantionului original;  - sarcina factoriala,
- sarcina factoriala,  – valoarea proprie corespunzătoare factorului j. Aceste valori calculate
– valoarea proprie corespunzătoare factorului j. Aceste valori calculate  sunt utilizate pe scară largă pentru a reprezenta grafic rezultatele analizei factoriale.
sunt utilizate pe scară largă pentru a reprezenta grafic rezultatele analizei factoriale.
Folosind matricea încărcărilor factorilor, matricea de corelație poate fi reconstruită:  .
.
Porțiunea de varianță a unei variabile explicată de componentele principale se numește comunalitate
 ,
,
Unde  - număr variabil și
- număr variabil și  - numărul componentei principale. Coeficienții de corelație restabiliți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile generalităților.
- numărul componentei principale. Coeficienții de corelație restabiliți numai din componentele principale vor fi mai mici decât cei inițiali în valoare absolută, iar pe diagonală nu vor fi 1, ci valorile generalităților.
Contribuție specifică  - componenta principală este determinată de formulă
- componenta principală este determinată de formulă
 .
.
Contribuția totală a contabilității  componentele principale sunt determinate din expresie
componentele principale sunt determinate din expresie
 .
.
Folosit de obicei pentru analiză  primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
primele componente principale, a căror contribuție la varianța totală depășește 60-70%.
Matricea de încărcare a factorilor A este utilizată pentru a interpreta componentele principale, luând în considerare de obicei acele valori mai mari de 0,5.
Valorile componentelor principale sunt specificate de matrice

APLICAREA METODEI COMPONENTELOR PRINCIPALE
PENTRU PRELUCRAREA DATELOR STATISTICE MULTIDIMENSIONALE
Sunt luate în considerare problemele procesării datelor statistice multidimensionale ale evaluărilor studenților pe baza aplicării metodei componentei principale.
Cuvinte cheie: analiza datelor multivariate, reducerea dimensionalității, metoda componentei principale, rating.
În practică, întâlnim adesea o situație în care obiectul de studiu este caracterizat de mulți parametri diferiți, fiecare dintre ei măsurați sau evaluați. Analiza matricei de date inițiale obținute ca urmare a studierii mai multor obiecte de același tip este o problemă practic de nerezolvat. Prin urmare, cercetătorul trebuie să analizeze conexiunile și interdependențele dintre parametrii inițiali pentru a le elimina pe unii dintre ei sau pentru a le înlocui cu un număr mai mic de orice funcții din aceștia, păstrând în același timp, dacă este posibil, toate informațiile conținute în aceștia.
În acest sens, se ridică sarcinile de reducere a dimensiunii, adică trecerea de la matricea de date inițială la un număr semnificativ mai mic de indicatori selectați dintre cei inițiali sau obținuți printr-o oarecare transformare a acestora (cu cea mai mică pierdere de informații conținute în originalul). matrice) și clasificare - separarea colecțiilor considerate de obiecte în grupuri omogene (într-un anumit sens). Dacă rezultatele unei anchete statistice a unui întreg set de obiecte au fost obținute pentru un număr mare de tipuri diferite și indicatori interrelaționați stocastic, atunci pentru a rezolva problemele de clasificare și reducerea dimensionalității, ar trebui să se utilizeze instrumentele de analiză statistică multivariată, în special metoda componentelor principale.
Articolul propune o metodologie de utilizare a metodei componentelor principale pentru prelucrarea datelor statistice multivariate. Ca exemplu, este dată soluția problemei prelucrării statistice a rezultatelor multidimensionale ale evaluării ratingului elevilor.
1. Determinarea și calculul componentelor principale..png" height="22 src="> caracteristici. Ca rezultat, obținem observații multidimensionale, fiecare dintre acestea putând fi reprezentată ca o observație vectorială
unde https://pandia.ru/text/79/206/images/image005.png" height="22 src=">.png" height="22 src="> este simbolul operației de transpunere.
Observațiile multidimensionale rezultate trebuie supuse unei prelucrări statistice..png" height="22 src=">.png" height="22 src=">.png" width="132" height="25 src=">. png" width ="33" height="22 src="> transformări permise ale caracteristicilor studiate 0 " style="border-collapse:collapse">

– starea de normalizare; | ||
| – condiția de ortogonalitate |

Obținut printr-o astfel de transformare https://pandia.ru/text/79/206/images/image018.png" width="79" height="23 src="> și reprezintă principalele componente. Din ele, în analiză ulterioară , sunt excluse variabilele cu varianță minimă , adică..png" width="131" height="22 src="> în transformarea (2)..png" width="13" height="22 src="> a acestei matrice sunt egale cu variațiile componentelor principale.
Astfel, prima componentă principală https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src=">este o astfel de combinație liniară normalizată-centrată a acestor indicatori , care dintre toate celelalte combinații similare are cea mai mare variație..png" width="12" height="22 src="> – vector propriu matrice https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">.png" width="80" height="23 src= " > este o combinație liniară normalizat-centrată a acestor indicatori care nu este corelată cu https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src=">. png" width="80" height="23 src="> sunt măsurate în diferite unități, rezultatele unui studiu al componentelor principale vor depinde în mod semnificativ de alegerea scării și de natura unităților de măsură și de combinațiile liniare rezultate a variabilelor originale va fi greu de interpretat. În acest sens, cu diferite unități de măsură ale caracteristicilor originale DIV_ADBLOCK310">
https://pandia.ru/text/79/206/images/image030.png" width="17" height="22 src=">.png" width="56" height="23 src=">. După o astfel de transformare, se efectuează o analiză a componentelor principale cu privire la valorile https://pandia.ru/text/79/206/images/image033.png" width="17" height="22 src= „> , care este, de asemenea, o matrice de corelare https://pandia.ru/text/79/206/images/image035.png" width="162" height="22 src=">.png" width="13" height=" 22 src="> la i- a doua caracteristică originală ..png" width="14" height="22 src=">.png" width="10" height="22 src="> este egală cu variația v- Componentele principale https://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> sunt folosite pentru interpretarea semnificativă a componentelor principale..png" lățime ="20" height="22 src=">.png" width="251" height="25 src=">
Pentru a efectua calcule, adunăm observațiile vectoriale într-o matrice de probă, în care rândurile corespund caracteristicilor controlate, iar coloanele corespund obiectelor de studiu (dimensiunea matricei - https://pandia.ru/text/79/206 /images/image043.png" width="348 " height="67 src=">
După centrarea datelor sursă, găsim matricea de corelație a eșantionului folosind formula
https://pandia.ru/text/79/206/images/image045.png" width="204" height="69 src=">
Elemente de matrice diagonală https://pandia.ru/text/79/206/images/image047.png" width="206" height="68 src=">
Elementele off-diagonale ale acestei matrice reprezintă estimări ale coeficienților de corelație dintre perechea corespunzătoare de caracteristici.
Compunem ecuația caracteristică pentru matricea 0 " style="margin-left:5.4pt;border-collapse:collapse">

Îi găsim toate rădăcinile:
Acum, pentru a găsi componentele vectorilor principali, înlocuim valorile numerice secvențiale https://pandia.ru/text/79/206/images/image065.png" width="16" height="22 src=" >.png" width="102" " height="24 src=">
De exemplu, cu https://pandia.ru/text/79/206/images/image069.png" width="262" height="70 src=">
Este evident că sistemul de ecuații rezultat este consistent datorită omogenității și este nedeterminat, adică are un număr infinit de soluții. Pentru a găsi singura soluție care ne interesează, vom folosi următoarele prevederi:
1. Pentru rădăcinile sistemului relația se poate scrie
https://pandia.ru/text/79/206/images/image071.png" width="20" height="23 src="> – adunare algebrică j al-lea element al oricărui i al-lea rând al matricei sistemului.
2. Prezența condiției de normalizare (2) asigură unicitatea soluției sistemului de ecuații luat în considerare..png" width="13" height="22 src=">, sunt determinate în mod unic, cu excepția faptului că toate ei pot schimba simultan semnul. Totuși, semnele vectorilor proprii ale componentelor nu joacă un rol semnificativ, deoarece modificarea lor nu afectează rezultatul analizei.
Astfel, obținem propriul nostru vector https://pandia.ru/text/79/206/images/image025.png" width="15" height="22 src=">:
https://pandia.ru/text/79/206/images/image024.png" width="12" height="22 src="> verificați pentru egalitate
https://pandia.ru/text/79/206/images/image076.png" width="503" height="22">
… … … … … … … … …
https://pandia.ru/text/79/206/images/image078.png" width="595" height="22 src=">
https://pandia.ru/text/79/206/images/image080.png" width="589" height="22 src=">
unde https://pandia.ru/text/79/206/images/image082.png" width="16" height="22 src=">.png" width="23" height="22 src="> – valori standardizate ale caracteristicilor inițiale corespunzătoare.
Compilarea unei matrice de transformare liniară ortogonală https://pandia.ru/text/79/206/images/image086.png" width="94" height="22 src=">
Deoarece, în conformitate cu proprietățile componentelor principale, suma variațiilor caracteristicilor originale este egală cu suma variațiilor tuturor componentelor principale, atunci, ținând cont de faptul că am considerat caracteristici inițiale normalizate, poate estima ce parte din variabilitatea totală a caracteristicilor originale este explicată de fiecare dintre componentele principale. De exemplu, pentru primele două componente principale avem:
|
|
Astfel, în conformitate cu criteriul de conținut informațional utilizat pentru componentele principale găsite din matricea de corelație, primele șapte componente principale explică 88,97% din variabilitatea totală a celor cincisprezece caracteristici originale.
Folosind matricea de transformare liniară https://pandia.ru/text/79/206/images/image038.png" width="10" height="22 src="> (pentru primele șapte componente principale):
https://pandia.ru/text/79/206/images/image090.png" width="16" height="22 src="> - numărul de diplome primite la concursul de lucrări științifice și de diplomă; https: //pandia .ru/text/79/206/images/image092.png" width="16" height="22 src=">.png" width="22" height="22 src=">.png" width=" 22" height="22 src=">.png" width="22" height="22 src="> – premii și premii câștigate la competiții sportive regionale, regionale și orășenești.
3..png" width="16" height="22 src=">(numărul de certificate bazat pe rezultatele participării la activități științifice și teze).
4..png" width="22" height="22 src=">(premii și premii câștigate la concursurile universitare).
6. A șasea componentă principală este corelată pozitiv cu indicatorul DIV_ADBLOCK311">
4. A treia componentă principală este activitatea elevilor în procesul de învățământ.
5. A patra și a șasea componentă sunt diligența studenților în semestrele de primăvară și, respectiv, de toamnă.
6. A cincea componentă principală este gradul de participare la competițiile sportive universitare.
Pe viitor, pentru a efectua toate calculele necesare la identificarea componentelor principale, se propune utilizarea unor sisteme software statistice specializate, de exemplu STATISTICA, care vor facilita semnificativ procesul de analiză.
Procesul de identificare a principalelor componente descrise în acest articol folosind exemplul evaluărilor studenților este propus pentru a fi utilizat pentru certificarea de licență și masterat.
BIBLIOGRAFIE
1. Statistică aplicată: Clasificare și reducerea dimensionalității: carte de referință. ed. / , ; editat de . – M.: Finanțe și Statistică, 1989. – 607 p.
2. Manual de statistică aplicată: în 2 volume: [trad. din engleză] / ed. E. Lloyd, W. Lederman, . – M.: Finanțe și Statistică, 1990. – T. 2. – 526 p.
3. Statistici aplicate. Fundamentele econometriei. În 2 volume T.1. Teoria probabilității și statistică aplicată: manual. pentru universități / , B. S. Mkhitaryan. – ed. a II-a, revăzută – M: UNITATEA-DANA, 2001. – 656 p.
4. Afifi, A. Analiza statistică: o abordare folosind un computer: [trad. din engleză] / A. Afifi, S. Eisen – M.: Mir, 1982. – 488 p.
5. Dronov, Analiză statistică: manual. indemnizație / . – Barna3. – 213 p.
6. Anderson, T. Introduction to multivariate statistical analysis / T. Anderson; BANDĂ din engleza [si etc.]; editat de . – M.: Stat. editura de fizica si matematica. lit., 1963. – 500 p.
7. Lawley, D. Analiza factorială ca metodă statistică / D. Lawley, A. Maxwell; BANDĂ din engleza . – M.: Mir, 1967. – 144 p.
8. Dubrov, metode statistice: manual /,. – M.: Finanțe și Statistică, 2003. – 352 p.
9. Kendall, M. Multivariate statistical analysis and time series / M. Kendall, A. Stewart; din engleza , ; editat de , . – M.: Nauka, 1976. – 736 p.
10. Beloglazov, analiză în probleme de calimetrie a educaţiei // Izv. RAS. Teorie și sisteme de control. – 2006. – Nr. 6. – P. 39 – 52.
Materialul a fost primit de redacție în data de 8.11.11.
Lucrarea a fost realizată în cadrul programului țintă federal „Personal științific și științific-pedagogic al Rusiei inovatoare” pentru 2009 – 2013. (contract de stat nr. P770).
 Reteta kebab de porc in sos de soia Inmuiati kebab de porc in sos de soia
Reteta kebab de porc in sos de soia Inmuiati kebab de porc in sos de soia Sărbătoarea Catedralei Sfinților din Kazan
Sărbătoarea Catedralei Sfinților din Kazan Femeia Cocoș-Scorpion: caracteristici, puncte forte și puncte slabe
Femeia Cocoș-Scorpion: caracteristici, puncte forte și puncte slabe